 Example Applications
Example Applications
Please see the Getting Started Guide for more information.
![]() Tip -
It's a good idea to modify one of the provided example apps to more closely match the needs of your organization.
Then, each time you start a new project, you have a starting point which is closer to your end goal.
Tip -
It's a good idea to modify one of the provided example apps to more closely match the needs of your organization.
Then, each time you start a new project, you have a starting point which is closer to your end goal.
For those looking for a more compact introduction to WEB4J, or for those with less experience with servlets, please see the tutorial.
WEB4J was not built like most tools, because it was not built with a specific implementation technique in mind. Rather, it was built with specific feelings or esthetics in mind. The basic steps were:
However, it does not seem possible to produce elegance without treating it as the single most important thing. Is Hibernate beautiful? Is all that XML configuration beautiful? Are its abundant cyclic references between packages beautiful? Is needing to configure the database schema in the application layer an elegant thing? Many would say "No, this is a bit ugly". And perhaps it was destined to be ugly, since it was based on an implementation idea, instead of on esthetic principles. If you wish to make something beautiful, you need to treat beauty as your Prime Directive.
Here are some typical line counts per feature, taken from a cross section of several features in the Fish & Chips Club example application. (Documentation comments are included in the line counts.)
| Item | Avg Lines | Relative Size |
|---|---|---|
| SQL file (.sql) | 25 | |
| Presentation (.jsp) | 108 | |
| Total | 133 | |
| Model (.java) | 111 | |
| Action (.java) | 144 | |
| DAO (.java) | 46 | |
| Total | 301 |
In general, your code will only be roughly twice the size of the non-code elements of your application.
It's often the case that the DAO class is simple, consisting only of a few single-line methods. In such cases, it's recommended that those DAO methods be refactored into the Action class. This will slightly reduce the total line count.
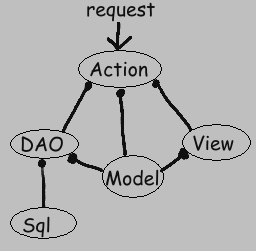
The above diagram shows the relationships between the elements found in a typical feature. The above notation means, for example, that the DAO uses the Model (and not the reverse). The View here is usually a Java Server Page.
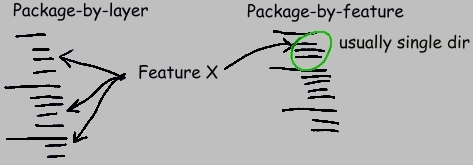
There are numerous advantages to this style. Although it may be unfamiliar to you, it's very likely that once you use it, you will find it superior to other styles.
If you do select this style, then you may find it convenient to use fixed, conventional names for both the view (the JSP) and the .sql file (which contains SQL statements), such as view.jsp and statements.sql. Using fixed names for the java classes is not recommended, however, since that would cause problems with javadoc, and would likely make your IDE less effective.
It's useful to treat your Action classes as the public face of each feature. That is, the javadoc of the Action should be the entry point into the rest of the implementation. In particular, it should link to the actual SQL statements and JSP. This is implememented in the example apps using two custom taglets. (Taglets are part of the javadoc tool.)
Example of their use:
/** * Edit Resto objects. * * @sql statements.sql * @view view.jsp */ public final class RestoAction ...These two taglets are defined in the WEB4J Developer Tools.
The primary job of a Model Object is to carry and validate data. Validation is especially important, since data is king. Most of the code in your Model Objects will deal with validation.
In WEB4J, validation is always placed in the constructor. If a validation fails, then a checked ModelCtorException must be thrown. When a validation fails, you cannot throw any other kind of exception except ModelCtorException. For example, if a required field is found to be null, then you cannot throw a NullPointerException. You must throw a ModelCtorException.
Some may object to this policy. However, you must remember that NullPointerException is an unchecked exception. Unchecked exceptions are strictly meant for bugs. Here's the important point: faulty user input is not a bug. It's to be expected as part of the normal operation of the program.
Validator and Check can help you validate your Model Objects. You are not required to use them, but you will likely find them convenient. The Check class returns common implementations of the Validator interface. For validations specific to your problem domain, you can define them as a new Validator, and then use them with the Check class, just like any other Validator.
![]() Recommendation -
Although it's not required, it's strongly recommended that your Model Objects be implemented as
immutable objects.
Implementing them as JavaBeans is not recommended, because of the problems linked to JavaBeans.
If some other tool happens to demand that your Model Object also be a JavaBean, then your Model Object can certainly add the required members, if needed, but WEB4J itself will never require them.
Recommendation -
Although it's not required, it's strongly recommended that your Model Objects be implemented as
immutable objects.
Implementing them as JavaBeans is not recommended, because of the problems linked to JavaBeans.
If some other tool happens to demand that your Model Object also be a JavaBean, then your Model Object can certainly add the required members, if needed, but WEB4J itself will never require them.
To always implement Model Objects safely, you need to understand that mutable object fields often need special care, in the form of a defensive copy.
The ModelUtil class is provided to help you correctly implement the toString, equals, and hashCode methods.
Your Model Objects can use the SafeText, Decimal, Id, and DateTime classes as building blocks, in the same way as Integer, Boolean, and so on. An Id can hold any kind of identifer you wish. SafeText should usually be used to model free-form user input, to avoid issues with Cross-Site Scripting attacks (see below). The Decimal class is the recommended replacement for BigDecimal, since it makes calculations much easier. The DateTime class is the recommended replacement for the widely reviled java.util.Date.
When modeling search criteria entered into a form, it's often possible to create a Model Object with package-private getXXX methods. As a general guideline, you should minimize the scope of methods and classes whenever possible.
![]() Recommendation - Model Objects are relatively simple "stand-alone" classes.
They aren't coupled directly to either the user interface, or to the database.
This makes them easy to unit test, using tools such as JUnit.
It's highly recommended that you unit test your Model Objects.
This will greatly increase your confidence in your validation code.
Recommendation - Model Objects are relatively simple "stand-alone" classes.
They aren't coupled directly to either the user interface, or to the database.
This makes them easy to unit test, using tools such as JUnit.
It's highly recommended that you unit test your Model Objects.
This will greatly increase your confidence in your validation code.
No extends Keyword
WEB4J isn't sensitive to the use of extends in your domain model. However, it's recommended that you avoid its use, since it's more difficult to work with. For further information, please see the topics in Joshua Bloch's Effective Java related to extends:
"There is no way to extend an instantiable class and add a value component while preserving the equals contract."
This means that the equals method is, in a sense, broken. If you need to extend a class, and add a new significant field, then it's not possible to provide a correct implementation of equals.
No 1..N Relations
Many are in the habit of hard-coding 1..N relations into the domain model, where one domain class has a List or Set of some other domain class. However, it can be strongly argued that it's better to avoid this, since it often doesn't correspond well with how different features use different data. For instance, take an example of a medical application, with 1 Doctor having N Patients. It's easy to imagine different features/screens having different needs:
Each feature uses different data. In some contexts, there's no need to refer to Patients at all. That is, there are common cases in which the underlying relation is of no relevance. To insist that the Doctor class must have an explicit, hard-coded relation to a Patient class disregards this fact. In effect, such a style promotes one particular use case to the detriment of the others.
On the other hand, if the Doctor and Patient classes are independent, then each feature/screen can simply retrieve the data as needed -- no more, and no less. If a feature needs to show a single Doctor along with a list of their Patients, then they are simply retrieved by the Action and placed into request scope. In effect, the relation is implemented in the Action, instead of the domain model. No wiring together of the objects is needed.
If you implement relations in your domain model, then you pay twice: first by defining an explicit link in your domain model, and then by ensuring that items are ignored in any context where they aren't needed. That's a lot of effort, for little benefit. In effect, this seems to create more problems than it solves.
There is a split among programmers between those who take data as king, and those who take the domain model as king. WEB4J agrees with those who take data is king, and as well with those who would like to keep domain classes as simple as possible.
Web4j has tools to help you implement persistence with a relational database, but you aren't forced to use them. If you want to use some other tool for persistence, then you can certainly do so. If you use web4j's data layer, then your DAO's will usually use the Db class.
Example code for some DAOs:
![]() Recommendation - When using package-by-feature, your DAO classes should be package-private by default.
You should increase their scope to public only when necessary.
If a DAO method needs to be visible from another package, then you will need to change the scope of the class to public.
However, this doesn't mean that all methods in the DAO should also be public.
Rather, just increase the scope only for those methods that really need it.
Recommendation - When using package-by-feature, your DAO classes should be package-private by default.
You should increase their scope to public only when necessary.
If a DAO method needs to be visible from another package, then you will need to change the scope of the class to public.
However, this doesn't mean that all methods in the DAO should also be public.
Rather, just increase the scope only for those methods that really need it.
![]() Tip - If a package-private DAO is small, it's often perfectly reasonable to remove the DAO class entirely, and place data access methods directly in the Action class.
This follows the general guideline that each of your classes should do a significant amount of work.
This style is used in the Fish & Chips Club example application in several places (for example, the Rating feature).
Tip - If a package-private DAO is small, it's often perfectly reasonable to remove the DAO class entirely, and place data access methods directly in the Action class.
This follows the general guideline that each of your classes should do a significant amount of work.
This style is used in the Fish & Chips Club example application in several places (for example, the Rating feature).
![]() Recommendation - Use one .sql file for each feature, in the same style as the example applications.
Using a single .sql file for the whole application mixes together unrelated features.
In addition, if more than one developer is working on the project, then developer contention for that single file will likely be a problem.
It's often simplest to use a fixed, conventional name for each .sql file, such as statements.sql.
Recommendation - Use one .sql file for each feature, in the same style as the example applications.
Using a single .sql file for the whole application mixes together unrelated features.
In addition, if more than one developer is working on the project, then developer contention for that single file will likely be a problem.
It's often simplest to use a fixed, conventional name for each .sql file, such as statements.sql.
The problem arises of how exactly these SQL statements are referenced in your source code. Incorrect references in code should be detected as soon as possible. Detecting them at compile time would be best, and detecting them at runtime would be worst. The approach taken by WEB4J is to detect bad references at startup time. This is not quite as effective as detecting such errors at compile time, but it's much more effective than detecting them at runtime.
At startup, WEB4J will read in all .sql files located under /WEB-INF/. It will also scan your code for all public static final SqlId fields. Then, these two sets are compared. WEB4J strictly enforces a one-to-one relation between the SqlId fields defined in your code, and the named statement blocks defined in your .sql files.
Here's an example. The statement named ADD_COMMENT (appearing in an .sql file) must correspond exactly to a single SqlId object (appearing in your code). The text passed to that SqlId's constructor must exactly match the name of the SQL statement.
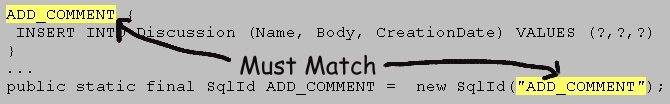
If any mismatch is found, then a RuntimeException is thrown, and your application will not be able to proceed. This protects you both from trivial naming errors and from 'cruft' (items that are no longer used), both in your code and in the .sql files.
The SqlId fields are what you use in code to reference items in your .sql files. They form the bridge between Java-land and SQL-land. For more information, please see the overview of the database package.
![]() Tip - It's occasionally useful to disable an .sql file.
To disable an .sql file, change its extension to .SQL (or anything else other than .sql).
WEB4J will only read in files having the .sql extension.
Tip - It's occasionally useful to disable an .sql file.
To disable an .sql file, change its extension to .SQL (or anything else other than .sql).
WEB4J will only read in files having the .sql extension.
Column Order of SELECTs and Model Object Constructors - The columns in a SELECT ResultSet must match one-to-one with corresponding arguments of the target Model Object constructor. Using this convention means that you don't have to perform tedious mapping between columns and Model Object setters.
Example: note how the constructor of Resto has arguments that correspond one-to-one to the SQL statements named LIST_RESTOS and FETCH_RESTO.
Order of Parameters Passed From DAO - SQL statements usually have one or more parameters, denoted by '?' placeholders in the underlying SQL. When your DAO passes data to such SQL statements, their order is taken as matching one-to-one with the corresponding '?' placeholders.
Let's take an example. For this entry in an .sql file:
ADD_RESTO {
INSERT INTO Resto (Name, Location, Price, Comment) VALUES (?,?,?,?)
}
The corresponding DAO method is:
Id add(Resto aResto) throws DAOException, DuplicateException {
Id result = Db.add(
ADD_RESTO,
aResto.getName(), aResto.getLocation(), aResto.getPrice(), aResto.getComment()
);
return result;
}
The important point is that the order of the sequence parameters passed to Db.add(SqlId, Object...) matches the underlying SQL.
The following code would be wrong, since Price and Comment are in the wrong order:
Id add(Resto aResto) throws DAOException, DuplicateException {
Id result = Db.add(
ADD_RESTO,
aResto.getName(), aResto.getLocation(), aResto.getComment(), aResto.getPrice()
);
return result;
}
![]() Warning - When testing, you should validate that the above conventions are being followed.
Warning - When testing, you should validate that the above conventions are being followed.
See below for more information.
Here are some examples:
If an appropriate Model Object already exists, then it should likely be used to return the required data, using the Db class.
If no Model Object exists for reporting a given set of data, then the Report class can be used. The Report class translates a ResultSet into a Map. It has several methods, corresponding to different policies for formatting the data.
The database names defined by ConnectionSource are used in your application as prefixes to identify which database a given operation is intended for. These prefixes are used in two places: in .sql files and in the corresponding SqlId fields (see above).
An entry in an .sql file versus the default database looks like this (block name has no prefix):
ADD_COMMENT { INSERT INTO Discussion (Name, Body, CreationDate) VALUES (?,?,?) } ... public static final SqlId ADD_COMMENT = new SqlId("ADD_COMMENT");An entry in an .sql file versus a non-default database named ACCESS_CONTROL looks like this (block name is prefixed with "ACCESS_CONTROL"):
ACCESS_CONTROL.USER_LIST { SELECT Name, Password FROM Users ORDER BY Name } ... public static final SqlId USER_LIST = new SqlId("ACCESS_CONTROL", "USER_LIST");Here, the prefix "ACCESS_CONTROL" is a database name defined by the ConnectionSource implementation.
The most common occurrence of this is in search operations. Search operations are implemented with a SELECT, but they differ from other SELECTs in an important way. In many cases, the user input which defines the search criteria can come in a large number of combinations. In those cases, enumeration of all possible combinations in your .sql file is often impractical. The DynamicSql class was created to help with this issue. It allows you to programmatically add the WHERE and ORDER BY clauses to base SQL statements (defined in the usual way in an .sql file). In this case, the static parts of the statement are placed in the .sql file, and the dynamic parts are appended in code. Before you use the DynamicSql class, you must have a good understanding of SQL injection attacks.
To use DynamicSql correctly, you need to parameterize user input:
See the example app's search feature for an illustration of using DynamicSql (especially the RestoSearchAction class).
There's another use case for DynamicSql as well. It's possible to create the entire SQL statement dynamically in code. In this case, there is still an entry in your .sql file, but it's an empty block. This allows you to to specify a non-default database name in the name of the block, if desired. It also allows WEB4J to apply the same processing as it usually does to your SqlId fields.
stringtype="unspecified"(This is usually done in the file that configures your connection pool DataSource.) If you don't turn on these conversions, then some calls to PreparedStatement.setString() made by web4j's data layer will fail. Please see the postgres JDBC driver documentation for more information.
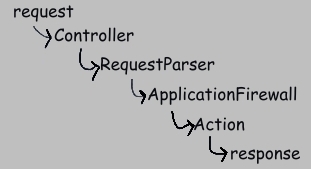
(Your code is almost always concerned with only the last 2 steps appearing above. You don't have to remember this structure. It's presented simply as background.)
By default, WEB4J uses a reasonable naming convention to map each incoming request to an Action. That convention is defined by RequestParserImpl. If you wish to use some other mechanism, then you will need to provide an alternate implementation of RequestParser.
Here's an example of the default Action mapping: given the Action class with fully qualified name of
hirondelle.fish.main.member.MemberEditthe implicit URI mapping is calculated as
/main/member/MemberEditThat is, the '.' character is changed to '/', and the prefix 'hirondelle.fish.' is removed. The prefix is configured in web.xml, with a setting named ImplicitMappingRemoveBasePackage.
This default mechanism also allows for simple explicit overrides: just add to your Action a String field of the conventional form:
public static final String EXPLICIT_URI_MAPPING = "/translate/basetext/BaseTextEdit";All Action mappings found by RequestParserImpl are logged during startup.
Once the Action class corresponding to the underlying request is found, then WEB4J creates an object of that class, and calls its execute method. That method performs the desired operation, and returns a ResponsePage, which tells WEB4J how you want to render the final response. The ResponsePage points to a JSP, and controls the forward versus redirect behavior.
It's strongly recommended that you review the various items below related to security.
WEB4J does its best to help you create secure web apps. In a few important cases it has built-in, default mechanisms which protect against certain kinds of attack:
In other cases, however, only optional mechanisms are available. For example, using SafeText to model free-form user input instead of String is highly recommended, but not absolutely mandatory. If you use these optional mechanisms correctly, then they will increase your confidence in the security of your app. It's important to realize that using WEB4J doesn't guarantee that your app is secure.
(Indeed, it does not seem possible for a web app framework to address all security problems. For example, how can a framework prevent you from storing passwords in clear text, or from using http when https is needed?)
For cases in which DynamicSql is used, please see the section on dynamic SQL for important information.
Cross-site scripting attacks are dangerous, common, and simple to perform. They are a major problem with web applications in general, and they should be taken very seriously. WEB4J takes the position that, in a web application, Strings containing free-form user input are a dangerous substance.
WEB4J provides SafeText as a replacement for String. SafeText will automatically escape special HTML characters in its toString() method. When needed, other escaping policies are available from SafeText, by calling its getXmlSafe() and getRawString() methods. The principal advantage is that JSP Expression Language can safely be used to render SafeText objects without worrying about special characters.
Tools such as <c:out> which manually escape free-form user input in the view will likely work - if you remember to use them. When using SafeText, however, the danger of forgetting to escape in the view does not exist. Hence, using SafeText will likely increase your confidence in the security of your application.
![]() Warning -
Many tools (including <c:out>) escape just 5 characters: &, <, >, " and '.
However, it's not clear if escaping just those 5 characters is sufficient to protect you from XSS attacks.
For example, the OWASP site lists 12 special characters that should be escaped.
In the interest of providing maximum protection, WEB4J takes an even more aggressive approach, and escapes
33 special characters.
Warning -
Many tools (including <c:out>) escape just 5 characters: &, <, >, " and '.
However, it's not clear if escaping just those 5 characters is sufficient to protect you from XSS attacks.
For example, the OWASP site lists 12 special characters that should be escaped.
In the interest of providing maximum protection, WEB4J takes an even more aggressive approach, and escapes
33 special characters.
SafeText has a second line of defense as well. In addition to escaping special characters, it allows you to specify a "white list" of acceptable characters. The white list is defined by your implementation of the PermittedCharacters interface. The default implementation will often be satisfactory.
The ConvertParam interface defines how building block classes are created out of request parameters, before being passed to Model Object constructors. The default implementation always allows SafeText, but it only conditionally allows Strings. This is controlled by the AllowStringAsBuildingBlock setting in web.xml. By default, that setting is turned off. That is the recommended setting. It provides maximum protection against XSS attacks. If you wish to allow your Model Objects to be built with Strings, then you must explicitly allow it.
![]() Recommendation -
Using String as a building block class is discouraged.
The SafeText class is recommended as a replacement for String, as a defence against Cross-Site Scripting (XSS) attacks.
Recommendation -
Using String as a building block class is discouraged.
The SafeText class is recommended as a replacement for String, as a defence against Cross-Site Scripting (XSS) attacks.
In WEB4J, you defend against CSRF attacks by performing the following:
The default ApplicationFirewallImpl works closely with RequestParameter. If an Action uses request parameters (and they usually do), then it must state explicitly what request parameters it expects: what their names are and what basic sanity checks should be performed on their values. That is done by declaring RequestParameter fields in the Action of the form (example):
public static final RequestParameter COMMENT = RequestParameter.withLengthCheck("Comment");
ApplicationFirewallImpl will perform hard validation on the incoming request parameters, both their names and values.
The soft validations are done in your code, usually in a Model Object constructor.
WEB4J helps in these ways:
In addition, the OWASP project recommends that a new session id should be created after every successful login. However, given the behavior of form-based login (as implemented in Tomcat, in any case) this doesn't seem possible to fully implement as desired. When Tomcat serves the login form, the session id is passed back to the client. Thus, the session id is served just before the user has successfully logged in, not after.
WEB4J usually logs at the FINE level. Log entries containing user data, however, are always logged at the FINEST level. In production, where the logging level is almost always higher than FINEST, such data will not appear in the log files at all.
The following two items are strongly recommended:
The SpamDetector interface and its SpamDetectorImpl help you prevent spam from getting into your database. Once you have decided on an implementation, it can be used in two ways.
![]() Tip -
Most spam contains links.
If it's expected that no links will form part of any end user input, then it's best to use the first style described above, and let the ApplicationFirewall automatically check every request parameter value for spam.
If there is a possibility of links appearing in user input, however, then the other style must be used.
Tip -
Most spam contains links.
If it's expected that no links will form part of any end user input, then it's best to use the first style described above, and let the ApplicationFirewall automatically check every request parameter value for spam.
If there is a possibility of links appearing in user input, however, then the other style must be used.
![]() Warning -
The SpamDetector helps you prevent spam, but it's not guaranteed to completely prevent it.
For public sites, you will often find that other tools (such as a CAPTCHA mechanism) will be required.
WEB4J does not itself include a CAPTCHA mechanism, but its Predictions example app uses the recaptcha tool, (along with recaptcha4j by Soren Davidsen).
Warning -
The SpamDetector helps you prevent spam, but it's not guaranteed to completely prevent it.
For public sites, you will often find that other tools (such as a CAPTCHA mechanism) will be required.
WEB4J does not itself include a CAPTCHA mechanism, but its Predictions example app uses the recaptcha tool, (along with recaptcha4j by Soren Davidsen).
<!-- /webmaster/* only for 'webmaster' Role -->
<web-app>
<security-constraint>
<web-resource-collection>
<web-resource-name>Webmaster Module</web-resource-name>
<url-pattern>/webmaster/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>webmaster</role-name>
</auth-constraint>
</security-constraint>
...
<security-role>
<role-name>webmaster</role-name>
</security-role>
</web-app>
When thinking of security, it's often useful to think in terms of nouns and verbs:
An effective alternative is to use the <url-pattern> to represent both the nouns and the verbs:
When using this technique, incoming URLs appear as follows:
The Member feature of the example app uses this technique.
When using this technique, you must also ensure that your <servlet-mapping> entries in web.xml allows for the various suffixes.
While the Servlet Specification allows for security constraints based on role (restrict-by-role), it says nothing about security constraints based on user (restrict-by-user). Internal intranet applications usually have restrict-by-role constraints, but public web applications usually have restrict-by-user constraints.
There are a number of ways to implement restrict-by-user constraints.
Users <- PredictionList <- PredictionThe Users table holds the user login name, password, and user id. Predictions are arranged in lists, and lists are owned by a single user. Each prediction links back to the Users table like this:
Prediction.PredictionListFK => PredictionList.Id PredictionList.UserFK => Users.IdOperations on the PredictionList table are simpler, since both the operation and its restrict-by-user constraint can usually be expressed in a single SQL statement. Some examples:
UPDATE PredictionList SET Title=? WHERE Id=? AND UserFK=? DELETE FROM PredictionList WHERE Id=? AND UserFK=? SELECT Id, Title, CreationDate, UserFK FROM PredictionList WHERE Id=? AND UserFK=?In each case, the value of the UserFK field is always passed in, to enforce the restrict-by-user constraint. Where does the value of UserFK come from? It's stored in session upon login.
This technique can't be used with INSERT operations, since they have no WHERE clause.
When a user logs in, the user login name (usually not the same as the id) is always placed into session scope by the servlet container. In most databases the user table will be normalized, such that the user id will be used as a foreign key in other tables (and not the user login name). When the WEB4J Controller detects successful logins, it calls your implementation of the LoginTasks interface. This is how you can add any 'extra' data to session scope - in this case, the user id. Thus, the user id can be easily passed to the above SQL statements.
It's important to realize that the user id is a server-side secret, and should never be displayed in a web page, or sent to the client in any way. It's critical for implementing restrict-by-user constraints, and the end user is not allowed to read or write its value. (Of course, the user's login name is not a server-side secret.)
The most compact technique is to use subqueries; in particular, a 'scalar' subquery that returns a single value, the user's id or login name. If your database supports subqueries, then a WHERE clause can usually be added to link back explicitly to the owner. As in the simpler case of a direct link described above, both the operation and the restrict-by-user constraint can still be performed with a single SQL statement.
Here's a deletion operation that uses a subquery to ensure that the owner of the record is the same as a logged in user, named 'bob':
DELETE FROM Prediction WHERE Id = 65498 AND ( SELECT Users.LoginName FROM Users JOIN PredictonList ON Users.Id = PredictionList.UserFK JOIN Prediction ON PredictionList.Id = Prediction.PredictionListFK WHERE Prediction.Id = 65498 ) = 'bob'Such subqueries can sometimes become difficult to read, because of the nesting. The .sql file format defined by WEB4J can help, since it gives you a simple mechanism to define items as variables, as in
-- first define the subquery
PredictionOwner {
SELECT
Users.LoginName
FROM
Users
JOIN
PredictonList ON Users.Id = PredictionList.UserFK
JOIN
Prediction ON PredictionList.Id = Prediction.PredictionListFK
WHERE
Prediction.Id = ?
}
-- then reference the subquery in the top-level operation
DELETE FROM Prediction
WHERE Id = ?
AND (${PredictionOwner}) = ?
This technique can't be used with INSERT operations, since they have no WHERE clause.
WEB4J offers a second way of implementing restrict-by-user constraints. This alternative can be used when:
The general idea is to use validated proxies for the user id. Continuing the example used above, remember that the Prediction table does not link directly to the Users table, since it's 2 steps away, not 1:
Prediction.PredictionListFK => PredictionList.Id PredictionList.UserFK => Users.IdThe PredictionAction handles all operations on predictions. Here's a listing of its URLs:
/PredictionAction.list?ParentId=5 /PredictionAction.fetchForChange?Id=7&ParentId=5 /PredictionAction.add?ParentId=5 /PredictionAction.change?Id=7&ParentId=5 /PredictionAction.delete?Id=7&ParentId=5Here, the ParentId is really a pointer to the PredictionList table. Its value is a proxy (a substitute) for the user id, since it eventually links back to the user. The problem is that when its value is passed from the client to the server as a ParentId request parameter, it's completely unvalidated, and cannot be used as a proxy for the user id without first validating it.
Validation can be done in 2 steps:
Step 1.
First, add an entry to web.xml of the form:
<init-param> <param-name>UntrustedProxyForUserId</param-name> <param-value> PredictionAction.* </param-value> </init-param>This entry identifies all requests in your application that have a restrict-by-user constraint that uses an unvalidated id. In this example, only one such constraint is defined, but you can define as many as you want, one per line. Thus, you can define all such constraints in a single spot. (See the javadoc for more information on the syntax of this entry.) This is useful since you can see all such constraints in a single place.
Step 2.
Second, the Action
(in this example,
PredictionAction)
must now implement the
FetchIdentifierOwner
interface, which has a single method:
Id fetchOwner() throws AppException;This method is implemented with a Data Access Object in the typical way, using the following underlying SELECT:
SELECT Users.LoginName FROM PredictionList, Users WHERE PredictionList.UserFK = Users.Id AND PredictionList.Id = ?The SELECT is essentially a simple lookup, which translates PredictionList.Id (the unvalidated proxy for the user id) into the login name of the person who "owns" that id. (This corresponds to the subquery mentioned earlier.) The WEB4J Controller then validates for you the result of this SELECT versus the login name stored in the current user's session. If they are the same, then the Action can continue; if not, then the Action is treated as a malicious request, is not processed any further, and an unpolished response is sent to the browser.
The Controller processes each request roughly as follows:
if the request uses an unvalidated proxy for the user id {
cast the Action into FetchIdentifierOwner
if the cast fails {
fail: do not process the request
else {
get the result of fetchOwner()
if it matches the user login name {
success: continue processing the request
}
else {
fail: do not process the request
}
}
}
Note that if you define the request as having a restrict-by-user constraint, and then forget to change your Action
to implement FetchIdentifierOwner, then the Action will fail. This protects you in case you forget.
In summary, WEB4J defines these items for validating proxies for the user id:
Here's a comparison of the two techniques for implementing restrict-by-user constraints:
| Item | Subquery | FetchIdentifierOwner |
|---|---|---|
| Database supports subqueries | Required | Not required |
| Number of SQL operations | 1 | 2 |
| Defined in one place | No | Partially |
| Needs coding in Action | No | Yes |
| Supports SELECT | Yes | Yes |
| Supports INSERT | No | Yes |
| Supports UPDATE | Yes | Yes |
| Supports DELETE | Yes | Yes |
![]() Tip -
It's useful to think of an Action as the public face of each feature.
That is, someone reading the javadoc of the Action should have a clear idea of what the Action really does, and the important parts of its implementation.
In WEB4J's example applications, the Actions usually declare the SqlId fields, and its javadoc has links to the underlying SQL statements and JSPs.
This style allows most DAOs to remain package-private. (Unfortunately, it's not usually possible to make the Model Object
package-private, since Model Object constructors and getXXX methods usually need to be public.)
Tip -
It's useful to think of an Action as the public face of each feature.
That is, someone reading the javadoc of the Action should have a clear idea of what the Action really does, and the important parts of its implementation.
In WEB4J's example applications, the Actions usually declare the SqlId fields, and its javadoc has links to the underlying SQL statements and JSPs.
This style allows most DAOs to remain package-private. (Unfortunately, it's not usually possible to make the Model Object
package-private, since Model Object constructors and getXXX methods usually need to be public.)
Action methods tend to be 'branchy'. This is natural, since Actions need to handle all the different possible errors that can occur. Here are some example Actions:
/** Update an existing {@link Visit}. */
protected void attemptChange() throws DAOException {
boolean success = fVisitDAO.change(fVisit);
if (success){
addMessage("Visit to _1_ changed successfully.", fVisit.getRestaurant());
}
else {
addError("No update occurred. Visit likely deleted by another user.");
}
}
In the background, the addMessage and addError methods will simply place a MessageList in session scope.
Session scope is used since many messages need to survive a redirect.
WEB4J does not currently have a mechanism for associating a message with a specific control in the JSP.
The example application displays messages with a reusable .tag file (see /WEB-INF/tags/displayMessages.tag), always placed at the top of a templated page. The alternative style of placing error messages near form controls is sometimes problematic:
Example
public static final RequestParameter MEMBER_ID = RequestParameter.withLengthCheck("Id");
public static final RequestParameter IS_ACTIVE = RequestParameter.withLengthCheck("Is Active");
public static final RequestParameter NAME = RequestParameter.withLengthCheck("Name");
...
/** Ensure user input can build a {@link Member}. */
protected void validateUserInput() {
try {
ModelFromRequest builder = new ModelFromRequest(getRequestParser());
fMember = builder.build(Member.class, MEMBER_ID, NAME, IS_ACTIVE);
}
catch (ModelCtorException ex){
addError(ex);
}
}
...
private Member fMember;
The first item passed to build is a class literal denoting the kind of Model Object to be built.
The remaining arguments to build represent the data (or pointers to the data) to be passed to the Model Object's constructor.
This method takes a sequence parameter, so any number of parameters can be passed.
It's important to note that the build method takes either RequestParameter objects, or any Java object.
If a RequestParameter is passed, however, then the underlying param is first translated into an appropriate base object such as Integer or BigDecimal before being passed to the Model Object constructor.
In the above example, the Model Object constructor has the form
public Member (Id aId, String aMemberName, Boolean aIsActive) ... {
...
}
That is, it does not take any RequestParameter objects as params.
Rather, the underlying data is translated into the desired target objects as required.
In the above example, the various RequestParameter objects passed to the build method are translated internally by WEB4J into an Id, String, and Boolean, corresponding to the declared parameters of the Model Object constructor.
There are numerous examples of building Model Objects in this way in the example application:
There are two use cases for the Populate tag: when there's no editing of an existing record, as in
<w:populate> ..form body... </w:populate>and when an existing item is being edited, as in
<w:populate using='some identifier'> ..form body... </w:populate>This second style requires that control names must match corresponding getXXX methods, using a naming convention. Let's take this example:
<w:populate using='item'> ... <input name="Message" type="text"> .... </w:populate>This implies that the item object has a public method named getMessage() whose return value can be used to populate the control named 'Message'. The return value is formatted into text using Formats.objectToText().
Forms that edit the database must have method=POST, while forms that perform searches or implement reports must have method=GET.
![]() Tip -
When getting started, the following items are the most important:
MailServerConfig,
MailServerCredentials,
Webmaster,
ImplicitMappingRemoveBasePackage,
LoggingDirectory,
TroubleTicketMailingList,
DefaultUserTimeZone,
and RedirectWelcomeFile. The rest of the items can usually be ignored.
Tip -
When getting started, the following items are the most important:
MailServerConfig,
MailServerCredentials,
Webmaster,
ImplicitMappingRemoveBasePackage,
LoggingDirectory,
TroubleTicketMailingList,
DefaultUserTimeZone,
and RedirectWelcomeFile. The rest of the items can usually be ignored.
If you're running in a Servlet 3.0 environment, and you find it annoying that these framework settings get in the way of your own config in web.xml, then you have the option of re-packaging these settings into a META-INF/web-fragment.xml file, and embedding it yourself into web4j.jar. (See § 8.2 of the Servlet 3.0 spec for more information.)
Webmaster
Email address of the application admin. No default value for this item.
If TroubleTickets are emailed by WEB4J, they will be sent to this
address. If emails are sent by WEB4J to other parties, then
they will have this as the "from" address.
This email address must be in the same domain as the MailServerConfig below.
ImplicitMappingRemoveBasePackage
Example value: 'com.blah' - do not include any trailing dot. No default value for this item.
By default, the RequestParserImpl class will map
Action classes implicitly to a specific URI.
This specific URI is constructed by taking the Action class name, and removing the 'base' package,
defined by this setting.
Example: given the settings in the example application, the class:
hirondelle.fish.main.home.HomePageActionis implicitly mapped to the URI:
/main/home/HomePageActionby removing 'hirondelle.fish.' from the (slightly modified) result of Class.getName().
Implicit mapping can always be overridden by specifying in the Action a conventional field named EXPLICIT_URI_MAPPING, of the form:
public static final String EXPLICIT_URI_MAPPING = "/main/Blah";
MailServerConfig
Controls how web4j will send emails on the application's behalf.
Default value: NONE.
Used to send trouble-ticket emails.
Name-value pairs of N properties to be used when connecting to the outgoing mail server.
Each name-value pair must appear on a separate line.
Example:
mail.host = smtp1.blah.net
mail.smtp.port = 465
If the special value "NONE" is supplied, then web4j will not send any emails.
MailServerCredentials
The user name and password for the outgoing mail server, separated by a pipe character '|'.
Default value: NONE.
If the special value "NONE" is supplied, then no credentials will be passed to the mail server (which,
in some cases, can still work).
LoggingDirectory
Location for logging file. Default value: NONE.
Example value: C:\log\fish\.
Used by LoggingConfigImpl.
Must end with a directory separator.
Special value of 'NONE' will disable LoggingConfigImpl, such that it will not
perform any logging config in code.
LoggingLevels
Logging levels for various loggers.
Used by LoggingConfigImpl.
Comma-separated list of items, in the same format as JDK logging.properties files:
com.wildebeest.myapp.level=INFO, hirondelle.web4j.level=FINEIt's recommended to include hirondelle.web4j.level, to allow logging by WEB4J classes. The default value for this item is:
hirondelle.web4j.level=CONFIGThe special value 'NONE' is also allowed for this item.
TroubleTicketMailingList
Comma-delimited list of one or more email addresses to be notified when
a problem occurs. If TroubleTickets are emailed, they will be sent to these addresses.
Default value 'NONE'.
MinimumIntervalBetweenTroubleTickets
Time interval in minutes. Suggested value: 30. Default value: 30.
TroubleTickets are expected to be rare. It's possible, however,
that TroubleTickets could be generated in large numbers in a
short period of time. For example, if the database connection is lost,
then a trouble ticket is generated with almost every request. This
parameter is used to throttle down the sending of such emails.
PoorPerformanceThreshold
Time interval in seconds. Suggested value: 20. Default value: 20.
If any request processed by the Controller takes more than
this number of seconds, then an email will be sent to the
configured Webmaster. The email will state the number of
milliseconds taken to process the request. Often, poor performance
is caused by degradation not in the web application itself,
but rather in the environment in which it's running.
MaxHttpRequestSize
Suggested value: 51200. Minimum value: 1000. Default value: 51200.
Maximum size in bytes of HTTP requests carrying no uploaded files.
If such a request has a total size in excess of this value, then it will
be discarded by WEB4J, and will not be made available to the application.
This is intended only for requests whose unusually large size identify them
clearly as hack requests.
MaxFileUploadRequestSize
Suggested value: 1048576. Minimum value: 1000. Default value: 51200.
Maximum size in bytes of HTTP requests carrying uploaded files.
If such a request has a total size in excess of this value, then it will
be discarded by WEB4J, and will not be made available to the application.
This is intended only for requests whose unusually large size identify them
clearly as hack requests.
MaxRequestParamValueSize
Suggested value: 51200. Minimum value: 1000. Default: 51200.
Maximum size in bytes of HTTP request parameter values.
This maximum is applied as a hard validation by ApplicationFirewallImpl,
and only against items created using the RequestParameter.withLengthCheck(String)
factory method. This is meant as a kind of default sanity check on parameter values,
when no other (more stringent) means of performing hard validation is suitable.
SpamDetectionInFirewall
Permitted values: ON and OFF. Default value: OFF.
When ON, then the default implementation of ApplicationFirewall will
use the configured SpamDetector to check the values of all request parameters.
If spam is detected, then an unpolished response will result.
FullyValidateFileUploads
Permitted values: ON and OFF. Default value: OFF.
Controls the behavior of ApplicationFirewallImpl
for file upload requests.
When ON, then ApplicationFirewallImpl will
treat file upload requests the same as any other request, and will check request parameter values in the usual way.
When OFF, then it will not perform such validation for file upload requests.
The problem addressed here is that file upload requests are fundamentally different from regular requests. In particular, access to request parameters is possible only if the file upload request has been 'wrapped' in some way, such that request parameters can be read in the usual way. This setting should be ON only if such request wrapping has been performed. Otherwise, it should be OFF.
AllowStringAsBuildingBlock
Permitted values: YES and NO. Default value: NO.
When YES, then the default implementation of ConvertParam will
allow String as a building block object, along with Integer, Date, and so on.
When set to NO, you will not be able to pass a String to any Model Object constructor, and you will need to use SafeText instead.
The idea here is that using SafeText is preferable to String.
Since String does not escape special characters, it's vulnerable to Cross-Site Scripting attacks.
UntrustedProxyForUserId
Default value: empty String. Lists all URLs having a Data Ownership Constraint implemented with an untrusted identifier.
The syntax of this entry is described by UntrustedProxyForUserIdImpl.
CharacterEncoding
Character encoding used in the application.
Default value is 'UTF-8'.
This setting MUST match the character encoding used by the database.
(Databases often use the term 'character set' for character encoding.)
Character encodings define how bytes are translated into text.
For more information, see the this link.
This setting will be used by the Controller to process requests. In addition, it will be used to create an application scope attribute named web4j_key_for_character_encoding. It's highly recommended that the value of this attribute be placed in template JSPs, so that all served pages will explicitly state the desired character encoding to be used by the browser. (This also increases security.)
DefaultLocale
Default Locale used by the application. Default value: en. This setting allows independence
of the server JRE's default Locale, and of HTTP headers.
See LocaleSource for information on how
a Locale is derived from an underlying request.
Example values : en, fr.
See also: java.util.Locale for possible values of Locale identifiers, and
Util.buildLocale(String).
DefaultUserTimeZone
Default TimeZone used by the application. Default value: GMT. This setting allows independence
of the server JRE's default TimeZone, and of HTTP headers.
See TimeZoneSource for information on how
a TimeZone is derived from an underlying request.
Example values: 'Canada/Montreal', 'UTC'.
See also: java.util.TimeZone for possible values of TimeZone identifiers,
and LocaleSource.
TimeZoneHint
Example values: 'NONE', 'Canada/Montreal', 'UTC'. Default value: 'NONE'.
See java.util.TimeZone for possible values of TimeZone identifiers.
This item is passed as hint to the database driver, for all java.util.Date columns encountered
by the WEB4J data layer. Overrides the JRE default time zone.
See: PreparedStatement.setTimestamp(int, Timestamp, Calendar) and
ResultSet.getTimestamp(int, Calendar).
The special value 'NONE' is used when the default JRE time zone suffices, or when
the database already stores time zone information in the desired manner.
DecimalSeparator
Comma-separated list of names of decimal separator characters to be accepted during
user input of numbers having a fractional part.
Permitted values : 'PERIOD', 'COMMA', 'PERIOD,COMMA'.
Default value: 'PERIOD'.
Used for conversions to BigDecimal and Decimal values.
This item is not affected by Locale.
BigDecimalDisplayFormat
Format for display of BigDecimal and Decimal values in reports. Default value: #,##0.00.
See java.text.DecimalFormat for possible values.
This pattern is non-localized. It's combined with a Locale to produce a locale-sensitive format.
BooleanTrueDisplayFormat
The text for presenting boolean 'true' values in a report.
Example values: Yes, True, Oui.
The HMTL spec states that form controls can appear outside of a form. One may specify a checkbox, as in:
<![CDATA[ <input type='checkbox' name='true' value='true' checked readonly notab> ]]>
The above is in fact the default value for this item. (CDATA is needed here because of the presence of special HTML characters.) Note that JSTL's c:out tag will need escapeXml set to false, in order to render such items as desired.
Another option is to use an IMG tag containing the desired image.
BooleanFalseDisplayFormat
The text for presenting boolean 'false' values in a report.
Example values: No, False, Non.
See BooleanTrueDisplayFormat for more information on this style.
The default value for this item is:
<![CDATA[ <input type='checkbox' name='false' value='false' checked readonly notab> ]]>
EmptyOrNullDisplayFormat
The text to display when an item has no value. Default value: '-' (a single hyphen).
Many browsers do not render empty TABLE cells very well.
The CSS 'empty-cells' property is the recommended way of
controlling this behavior.
As an alternative, this setting may be used to specify text
representing empty or null items in a report.
Example values: '-', '...'
IntegerDisplayFormat
The format for presenting integer quantities. Default value: #,###.
See java.text.DecimalFormat for possible values.
This pattern is non-localized. It's combined with a Locale
to produce a locale-sensitive format.
IgnorableParamValue
Any parameter which takes this value will be ignored, by having its
value replaced by an empty string, in RequestParser.
Default value is an empty String.
Intended solely for SELECT tags, which show a list of items. Even when no selection is made by the user, most browsers will simply pass the first item in the SELECT as the parameter value. If such behavior is undesired, then specify this parameter, and put the IgnorableParamValue as the first item in the SELECT tag.
Typically, one would place unusual characters in IgnorableParamValue, to greatly reduce the likelihood of conflict with regular user input. You may specify an empty value as well, which corresponds to a blank initial value in the list.
In a multilingual application, this setting must not contain translatable text. For example, '----' or an empty string would be an appropriate value for a multilingual application.
IsSQLPrecompilationAttempted
Value: (true | false). Default value: true.
If true, then upon startup WEB4J will attempt to precompile SQL statements
appearing in the .sql file(s), by calling Connection.prepareStatement(String), and
detecting if an SQLException is thrown. Any detected errors are logged as SEVERE.
It's important to note that some drivers/databases will NOT throw an SQLException even when the text is syntactically invalid. (This can be determined with a simple test.) Hence, this is always an "attempt" to precompile.
The idea here is to be defensive, and to attempt to detect errors as soon as possible. In addition, this service is very useful when porting an application to a new database: one may start with the "old" statements, and begin by seeing if they compile versus the "new" database. Recommended value is 'true', unless certain the driver/database does not support precompilation in this manner. See SqlId for more information.
MaxRows
Upper limit on the number of rows to be returned by any
SELECT statement. Default value: 300. Serves as a defensive safety measure, to help
avoid operations which may take an excessively long time.
Set value to '0' to turn off this limit.
This value is passed to Statement.setMaxRows(int).
FetchSize
Hint sent to JDBC driver regarding the number of rows to be returned
when more rows are needed. Default size: 25. Applies only to SELECT statements.
Set value to '0' to turn off this hint.
This value is passed to Statement.setFetchSize(int).
HasAutoGeneratedKeys
Value: (true | false), ignores case. Default value: false.
Indicates if the database and driver support the method
Connection.prepareStatement(SqlText, Statement.RETURN_GENERATED_KEYS).
ErrorCodeForDuplicateKey
The error code(s) returned by SQLException.getErrorCode()
when trying to add a duplicate record. Default value: 1 (Oracle's value).
If you wish to treat more than one error code as being related to
duplicate key constraints, you may specify a comma-delimited list of integers.
If this error code is unknown for a given database, you may
determine its value by exercising your application, and
deliberately causing the error to happen.
When web4j detects these error codes, then it will throw a
DuplicateException, instead of a DAOException.
Some confirmed values for this item:
| Oracle | 1 (default) |
| MySQL | 1062 |
| JavaDB/Derby | -1 |
Some unconfirmed values for this item:
| SqlServer | 2627 |
| DB2 | -803 |
| Sybase | 2601 |
ErrorCodeForForeignKey
The integer error code(s) returned by SQLException.getErrorCode()
when a foreign key constraint fails.
If you wish to treat more than one error code as being related to
foreign key constraints, you may specify a comma-delimited list of integers.
If this error code is unknown for a given database, you may
determine its value by exercising the example application, and
deliberately causing the error to happen.
When web4j detects these error codes, then it will throw a
ForeignKeyException, instead of a DAOException.
Some example values (please confirm using your database documentation):
| Oracle | 2291 (default) |
| MySQL | 1216,1217,1451,1452 |
| JavaDB/Derby | 23503 |
SqlFetcherDefaultTxIsolationLevel
The default transaction isolation level used for queries.
Default value: DATABASE_DEFAULT.
The permitted values are:
| DATABASE_DEFAULT (recommended) |
| SERIALIZABLE |
| REPEATABLE_READ |
| READ_COMMITTED |
| READ_UNCOMMITTED (not recommended !) |
For more information, see TxIsolationLevel, and java.sql.Connection. It's important to confirm support for these levels with your database documentation.
SqlEditorDefaultTxIsolationLevel
The default transaction isolation level used for edit operations.
Default value: DATABASE_DEFAULT.
The permitted values are:
| DATABASE_DEFAULT (recommended) |
| SERIALIZABLE |
| REPEATABLE_READ |
| READ_COMMITTED |
| READ_UNCOMMITTED (not recommended !) |
For more information, see TxIsolationLevel, and java.sql.Connection. It's important to confirm support for these levels with your database documentation.
DateTimeFormatForPassingParamsToDb
Formats used when passing DateTime objects as
parameters to SQL statements.
Default value: YYYY-MM-DD^hh:mm:ss^YYYY-MM-DD hh:mm:ss
Three formats must be specified here, corresponding to 3 common cases (in this order):
The format Strings are those defined by DateTime. The 3 format Strings are separated by a ^ character.
If a DateTime parameter to an SQL statement needs to be passed in a format which is not specified here, simply format the DateTime in your code as desired, and pass the result to the database as a fully formatted String, instead of a DateTime.
RedirectWelcomeFile
Simple servlet for redirecting directory requests to the home page Action.
The source code underlying this item is provided with the example application.
It doesn't form part of the WEB4J core.
Example value appropriate for development:
http://localhost:8080/fish/main/home/HomePageAction.show
100~Translation=200~AccessControl=300The '~' character is used as a separator. Here, the first entry '100' represents the setting for the default database. It also represents the setting for all other databases, unless an override value is provided by one of the 'name=value' pairs. Thus, the above represents:
| Database Name | Value |
|---|---|
| [the default db] | 100 |
| Translation | 200 |
| AccessControl | 300 |
| [any other db name] | 100 |
There is a single exception - the TimeZoneHint setting can only take a single value, to be applied across all databases. (The reason for this unfortunate exception is simply that changing it would have a large number of ripple effects, and would represent too much pain for too little gain.)
This syntax is particularly useful for applications which use not only multiple databases, but also multiple database vendors (MySQL and PostgreSQL in the same application, for example).
The BuildImpl class controls the lookup of implementations. BuildImpl makes a distinction between three kinds of implementations, described below.
The conventional package name is always 'hirondelle.web4j.config', while the conventional class name varies. Please see below for a complete listing.
<init-param> <param-name>ImplementationFor.hirondelle.web4j.ApplicationInfo</param-name> <param-value>com.xyz.MyAppInfo</param-value> <description> Package-qualified name of class describing simple, high level information about this application. </description> </init-param>That is, for the interface hirondelle.web4j.ApplicationInfo, your implementation class is com.xyz.MyAppInfo.
Upon startup, the BuildImpl class searches for implementations in the following order:
See BuildImpl for further information.
![]() Recommendation -
The conventional-name style is preferred over the arbitrary-name style.
The conventional-name style takes less effort, and does not require an associated entry in a text file.
Recommendation -
The conventional-name style is preferred over the arbitrary-name style.
The conventional-name style takes less effort, and does not require an associated entry in a text file.
| Question | Interface | Conventional Impl Name, in hirondelle.web4j.config | Default/Example Implementation |
|---|---|---|---|
| What is the application's name, version, build date, and so on? | ApplicationInfo | AppInfo | example |
| What tasks need to be performed during startup? | StartupTasks | Startup | example |
| What tasks need to be performed after a user successfully logs in? | LoginTasks | Login | example |
| What Action is related to each request? | RequestParser (an ABC) | RequestToAction | RequestParserImpl |
| Which requests should be treated as malicious attacks? | ApplicationFirewall | AppFirewall | ApplicationFirewallImpl |
| Which requests use untrusted proxies for the user id? | UntrustedProxyForUserId | OwnerFirewall | UntrustedProxyForUserIdImpl |
| How is spam distinguished from regular user input? | SpamDetector | SpamDetect | SpamDetectorImpl |
| How is a request param translated into a given target type? | ConvertParam | ConvertParams | ConvertParamImpl |
| How does the application respond when a low level conversion error takes place when parsing user input? | ConvertParamError | ConvertParamErrorImpl | example |
| What characters are permitted for text input fields? | PermittedCharacters | PermittedChars | PermittedCharactersImpl |
| How are dates and times formatted and parsed? | DateConverter | DateConverterImpl | example |
| How is a Locale derived from the request? | LocaleSource | LocaleSrc | LocaleSourceImpl |
| How is the system clock defined? | TimeSource | TimeSrc | TimeSourceImpl |
| How is a TimeZone derived from the request? | TimeZoneSource | TimeZoneSrc | TimeZoneSourceImpl |
| What is the translation of this text, for a given Locale? | Translator | TranslatorImpl | example |
| How does the application obtain a database Connection? | ConnectionSource | ConnectionSrc | example |
| How is a ResultSet column translated into a given target type? | ConvertColumn | ColToObject | ConvertColumnImpl |
| How should an email be sent when a problem occurs? | Emailer | EmailerImpl | |
| How should the logging system be configured? | LoggingConfig | LogConfig | LoggingConfigImpl |

WEB4J's translation package has a number of items to help you implement multilingual applications. The most important item is the Translator interface. This interface will usually be implemented using either ResourceBundles or a database. In addition, this interface works closely with your implementation of the LocaleSource interface, which defines the end user's preferred language.
![]() Recommendation -
Using a database to store translations has numerous advantages over using ResourceBundle, since ResourceBundle has a number of annoying defects.
For illustration of using a database, please see the Fish & Chips Club example application.
(Please note that in the Fish & Chips Club, not all French translations are actually provided.
This is to allow you to exercise the mechanism for adding translations at runtime.)
Recommendation -
Using a database to store translations has numerous advantages over using ResourceBundle, since ResourceBundle has a number of annoying defects.
For illustration of using a database, please see the Fish & Chips Club example application.
(Please note that in the Fish & Chips Club, not all French translations are actually provided.
This is to allow you to exercise the mechanism for adding translations at runtime.)
Natural-language base text and coder-key base text differ slightly in their behavior. To illustrate this difference, let's take an example of an app that is developed in English and presented to the user in two languages, English and French. In this case, English is the base language. When the user's language preference is English, any natural language base text such as 'Add/Edit' can be presented to the end user as is, without further processing. However, if a coder key such as 'add.edit.button' is used instead, then such text is always going to need further processing, even when the user's preferred language is English. One might think of coder keys as being in a kind of special language known only to the programmer. Thus, coder keys always need translation, even into the base language of the application.
![]() Recommendation -
Natural language base text should be preferred over coder keys.
When reading source code, natural language base text is more legible than coder keys.
In addition, coder keys cannot be presented as-is to the end user, so they increase the effort needed to implement translation.
Recommendation -
Natural language base text should be preferred over coder keys.
When reading source code, natural language base text is more legible than coder keys.
In addition, coder keys cannot be presented as-is to the end user, so they increase the effort needed to implement translation.
The following tags implement translation in your JSPs:
Storing translations in application scope allows you to avoid the cost of repeated database lookups for data which rarely changes.
Such a design is implemented by subclassing the Controller. By providing an override of its swapResponsePage method, you can alter the default mechanism used by WEB4J to find the ResponsePage returned by your Actions. For example, a page referenced as 'Blah.jsp' in your Action can be changed by your custom Controller, late in processing, to actually refer to some other item such as 'Blah_en.jsp' or 'Blah_fr.jsp', according to the given Locale. (See LocaleSource for more information on Locales.)
The Visit feature of the Fish & Chips Club example application can be used to demonstrate this technique. To exercise it, you simply need to change the servlet-class entry in web.xml, to point to the Visit feature's CustomController.
When the same encoding is not used with 100% consistency across all parts of your application, then your users will see annoying '?' (or similar) symbols where regular text should appear. Such problems are common, and they're very annoying.
The primary defense here is to use the UTF-8 encoding. UTF-8 can represent almost any kind of text. In a perfect world, all tools would default to UTF-8. In practice, the problem is that many tools default to non-UTF-8 encodings. For example:
One of the problems with encodings is that they're hard to determine precisely simply by examining the raw bytes. Hence, various means have been concocted to get around the fact that encodings are not stated explicitly within the bytes themselves. For example, the first line of an XML file can appear as:
<?xml version="1.0" encoding="UTF-8"?>But here's the catch - if this doesn't match the encoding with which the file was really saved, then it's wrong. You have to manually ensure that the stated encoding matches the actual one. The stated encoding above says "I saved this file using UTF-8". If that's not true, then the statement is false, and problems will result.
It's natural to regard these encoding settings as specifying the encoding. But that's false; it's not a specification of the encoding, it's a (possibly incorrect) attempt to communicate the encoding. There's a big difference. (In practice, there are many such instances of mismatch between the stated and actual encoding.)
The JSP specification allows you to communicate the page character encoding in various ways. For JSP files that use standard (non-XML) syntax, the logic used to determine the intended page character encoding has the following order of evaluation:
1. JSP config in web.xml:
<jsp-config>
<jsp-property-group>
<url-pattern>/*</url-pattern>
<page-encoding>UTF-8</page-encoding>
</jsp-property-group>
</jsp-config>
2. <%@ page pageEncoding="UTF-8"%>
3. <%@ page contentType="text/html;charset=UTF-8"%>
4. Default to ISO-8859-1
Tag files are a bit different. They aren't as flexible as JSPs, and you can't state the intended encoding as part of jsp-config in web.xml.
With tag files, the order of evaluation is simply:
1. <%@ tag pageEncoding="UTF-8"%> 2. Default to ISO-8859-1
The only job of the JSP, in this case, is to let you control header information. Even though you are serving structured data, that data is still being passed around using HTTP, and every HTTP response should include headers for the content-type and encoding.
The Predictions example app has a simple example of serving JSON data. It's implemented by:
Of course, the exact same technique can be used to serve data in any other format.
The WEB4J framework classes (and the example apps) use JDK logging. It's recommended that you configure JDK logging to view WEB4J's logging output, by configuring the JDK logging tool. You might get away with configuring logging.properties, but in a shared environment on a server, that will likely be inadequate: the Handlers (output files) defined in logging.properties are per JRE, not per web application. That means that different web apps will output to the same logging file.
To address that problem, the LoggingConfig interface and its default LoggingConfigImpl have been provided to allow a programmatic way of configuring logging (if you will permit that somewhat contradictory expression). This programmatic style is per class loader, not per JRE, so its Handlers (output files) are not shared between applications.
The default LoggingConfigImpl has the interesting property of allowing you to log records with a time stamp derived from your application's fake system clock. This is because it uses a TimeSource.
The most common start-up task involves code tables. A code table is an enumeration or list of related items in the problem domain. For example, these kinds of items might be implemented as code tables:
The Code class is provided to help you implement code tables. You are not obliged to use it.
In a multilingual application backed by a database, another common startup task is to place all translations into application scope. Thus, your Translator implementation can access in-memory data, instead of continually querying the database for these relatively unimportant items which rarely change.
The single method of the StartupTasks interface has two arguments. The second argument is the name of a database, as you have defined in your implementation of the ConnectionSource interface. Upon startup, WEB4J attempts to connect to each of your databases. As each attempt succeeds, the framework will pass the database name to your StartupTasks implementation.
Your implementation should follow this form:
public void startApplication(ServletConfig aConfig, String aDbName) throws DAOException {
if (!Util.textHasContent(aDbName)){
//tasks not related to any db - this is called first
}
else if (ConnectionSrc.DEFAULT.equals(aDbName)){
//tasks related to this db
}
else if (ConnectionSrc.TRANSLATION.equals(aDbName)){
//tasks related to this db
}
}
What happens if one or more databases are down when your app starts? If that occurs, the framework will try to connect to any remaining 'bad' databases, with each incoming request. If a connection is found, then, as usual, the framework will pass the database name to your StartupTasks implementation.
Version 3.0 of the Servlet API (published January, 2010) has good support for file uploads. If it's available to you, you should use it to access uploaded binary data.
Servlet API version 2.5 (upon which web4j is still based) has surprisingly poor support for file uploads. When using Servlet 2.5, third-party tools such as the Apache Commons FileUpload tool are needed. This technique uses a filter and a request wrapper, and is demonstrated in the file upload feature of the Fish & Chips Club example app.
Regardless of which technique you use to access the uploaded data, it's made available to your Action as an InputStream. Web4j includes InputStream as one of its base building block classes, for constructing Model Objects, and for passing data into and out of the database.
When an InputStream is passed to the database, setBinaryStream(int, InputStream) is used. This method is available in Java 6+, and may not be supported by older drivers. For example, Tomcat 6 has an older connection pool implementation, and it doesn't support the above method, while Tomcat 7 has no such problem. Note that this issue is related to the level of support of JDBC, not of the Servlet API.
Form controls: browsers don't seem to respect the value attribute of form input controls. This makes it impossible for web4j (or any other tool) to dynamically pre-populate the selected file. Thus, any update operations on binary data will usually need some extra care. (The simplest implementations would provide only add and delete operations, with no update operation as such.)
The RequestParser class is able to translate RequestParameter objects into building block classes. The one exception is InputStream. When you need to build a Model Object that takes an InputStream, you will have to pass the InputStream directly, without going through an intermediate RequestParameter. This minor nuisance will be removed when web4j moves to Servlet 3.0 as its base API.
The Pager tag lets you emit links corresponding to the first, next, or previous page. The links don't perform the actual 'subsetting' of the data. That's done elsewhere, in one of 3 possible places:
Please see the Pager javadoc for further information. As well, the Fish & Chips Club example application implements paging in its Discussion feature, where users post comments to a simple message board.
![]() Warning - The paging mechanism is a bit confusing. It depends on several items cooperating together: request parameters, the Pager tag, and the chosen subsetting mechanism.
The subsetting mechanism in turn comes in 3 different styles, as stated above.
Please read the Pager javadoc carefully to make sure you understand how it works.
Warning - The paging mechanism is a bit confusing. It depends on several items cooperating together: request parameters, the Pager tag, and the chosen subsetting mechanism.
The subsetting mechanism in turn comes in 3 different styles, as stated above.
Please read the Pager javadoc carefully to make sure you understand how it works.
In the following cases, such double-submits are not an issue:
When you use the database layer outside of a servlet context, you need to supply an implementation of ConnectionSource (as usual), and two collections. The collections define two things:
Here's an example:
//config settings
Map<String, String> settings = new LinkedHashMap<String, String>();
//theses settings override the default settings
settings.put("Webmaster", "blah");
settings.put("ImplicitMappingRemoveBasePackage", "blah");
//no real need to use SafeText for a command line app
settings.put("AllowStringAsBuildingBlock", "true");
//optional logging settings
settings.put("LoggingDirectory", "C:\\log\\blah\\");
settings.put("LoggingLevels", "hirondelle.web4j.level=FINEST");
settings.put("HasAutoGeneratedKeys", "true");
//override any other default settings here
//fetch the raw SQL statement data
//the FindSql class is defined by your app; it scans
//the local file system for .sql files
FindSql findSql = new FindSql(new File(System.getProperty("user.dir") + "\\bin\\"));
List<String> rawSqls = findSql.scan();
//pass the config data and sql statements to this single call
Db.initStandalone(settings, rawSqls);
//now you can use the database layer in the usual way
To specify your implementation of the ConnectionSource interface, you just make
use of the same mechanisms as usual.
Most will simply place their implementation in their app, using the
conventional package name hirondelle.web4j.config, and the conventional class name
ConnectionSrc. Alternatively, you can use the 'settings' map to specify the
implementation (in the same way you would specify it in web.xml), using
the name
ImplementationFor.hirondelle.web4j.database.ConnectionSourceSee above for more information.
If you use the Reports class, then you may also need to supply an implementation for a second interface: DateConverter.
In the above example, a FindSql class is referenced. You will need to create such a class, to find the SQL statements defined by your app. Typically, that class will need to scan the file system under a specific root directory (or perhaps in a jar), find all the .sql files, and read in their content using the correct encoding. Each file will be represented as a single String in the list passed to the Db class. In the context of a web app, this is performed by the framework upon startup. The reason this is possible for a web app is that the file and directory structure is well-defined for web apps, and the framework knows where to look for things. Outside of the servlet context, however, the location of that data becomes ambiguous, so your app needs to supply it explicitly.
Using the above code, the initialization tasks performed by Db.initStandalone are not as complete as those performed in a servlet context. In short, the validation and logging tasks are skipped. (The reason is the same as above: the location of items is ambiguous). For example, the SqlId's used in your code are not matched one-to-one with the corresponding names in your .sql files. In the absence of such validations, any errors, if present, will appear at run-time instead of at start-up.
Different organizations take different approaches to unit testing. Some aggressively unit test all classes, while others prefer to focus on areas most likely to contain bugs. (Many casual applications don't include any unit tests at all.)
For an illustration of unit testing, please see the following packages in the Fish & Chips Club example application:
To run the tests in the Fish example app, perform the following:
WEB4J helps you implement unit tests by providing test doubles. Using the terminology of Gerard Meszaros and Martin Fowler, these test doubles are fake objects (not mock objects). Such fake objects serve to mimic the real runtime environment of a class, using implementations you can control as desired.
The example application includes source code for the following fake objects:
These test doubles implement the methods most likely needed during unit testing. If, for some reason, these fake implementations don't allow you to perform certain tests, then you can simply edit them as desired. (It's not expected that this will be commonly required.)These fake objects make a number of simplifying assumptions. The most important is that only a single thread of execution is assumed.
Also included is the source code for some utilities you may find useful:
See the TESTAll.initControllerIfNeeded() method in the example app for an illustration.
There are also 2 methods in BuildImpl which were created specifically for creating a proper test environment:
It's useful to test explicitly for ordering errors. In general, you will find more ordering errors if you test with data that clearly distinguishes between different fields/columns.
To illustrate, here's an example using two fields/columns in Member objects (taken from the example app):
| Disposition | IsActive | |
|---|---|---|
| Java Type | Id | Boolean |
| Column Type | MediumInt | TinyInt |
| Similar Values (bad) | 1 | 1 |
| Distinct Values (good) | 1 | 4 |
If there is a permutation error involving Disposition and IsActive, and if you use similar values for these fields during testing, then the permutation error will not be detected. If you use distinct values, then any permutation error will be detected.
So, the guideline is to make sure your test data distinguishes clearly between fields/columns. It's likely best to avoid common, generic values such as 0, 1, nulls, and empty Strings.
Instead of fake DAOs, you might also consider a fake relational database.
WEB4J provides the TimeSource interface to help you implement a fake system clock. When you define such a TimeSource, you are both defining a fake system clock for your application, and you are sharing your fake system clock with WEB4J framework classes. Thus, your application and the framework can use exactly the same clock, and will remain synchronized.
In addition, this same mechanism allows the default logging mechanism to timestamp records with your fake system clock time. See javapractices.com for an example.
The following is an outline of the recommended steps to follow to build a new application. The general idea is that the example application coexists with your app until it's no longer needed.
1 - Download the latest version of fish.zip. Get it running, using the Getting Started Guide. Make sure the application can be launched and run before proceeding further. Note that .class files are included with fish.zip, so it's not necessary (or recommended) at this stage to compile the source. After each of the remaining steps, it's a good idea to verify that the application remains unbroken for each completed step.
2 - Change the base package/directory from 'hirondelle.fish' to the appropriate value for your new app. The supplied build.xml has an ANT target to help you:
In web.xml, scan for settings which depend on the base package, and update them:
3 - Create databases of the correct name.
There are two ways to update the database name:
At this stage, databases of the correct name exist, but their tables are temporary; the 'real' tables will be added later.
If MySQL is not available, then the database script will need to be ported to the target database. Although that may sound onerous, it's usually not that much work.
4 - Update the server configuration as needed. The connection pool and security realm info will need to reflect the new database names.
5 - edit hirondelle.config.web4j.AppInfo to reflect the correct information.
At the end of this phase :
New tables should be added beside the existing ones. Do not remove the tables from the example app - not yet. In the beginning, your tables and the tables of the example application will coexist, side by side.
Modify Template.jsp, Footer.jsp, stylesheets, and so on, to create the basic look of your new application. It's often useful to create menu links at this stage as well.
New features (JSPs, code, and .sql files) should be placed beside existing features, in their own packages. Again, don't worry too much about removing existing items until later in development.
Usually, a feature will have these parts :
In most cases, removing a feature reduces to two simple actions : removing a single directory, and removing a menu link from some related template JSP.
For instance, the example app places user access tables in a database separate from the main business domain. Your app design may call for these items to be placed in one and the same database. Or, it may call for JNDI lookup to be used instead.
The version numbers of the example apps reflects the version of web4j.jar with which it was built. For example, version 3.0.0.1 of the example app was built with version 3.0.0 of web4j.jar.